Table of Contents
Top Ten RAID Tips
Источник: http://www.raidtips.com/
Getting your requirements straight
When you are about to build a RAID, make sure you understand your storage requirements. The following points are significant:
- Array capacity. Whatever your capacity requirements are, these are underestimated, most likely by the factor of two.
- Budget limits.
- Expected activity profile, especially read-to-write ratio. If there are mostly reads and few writes, then RAID 5 or RAID 6 would be OK. If significant random write activity is expected, consider RAID 10 instead.
- Expected lifetime. Whatever the projected lifetime of the storage system is, it is underestimated.
- For a quick estimation of capacities for various RAID levels, check the online RAID calculator.
The RAID triangle
The relationship between Speed, Price, and Fault Tolerance mostly determines the RAID level to use. Of these three parameters, pick any two and you are all set.
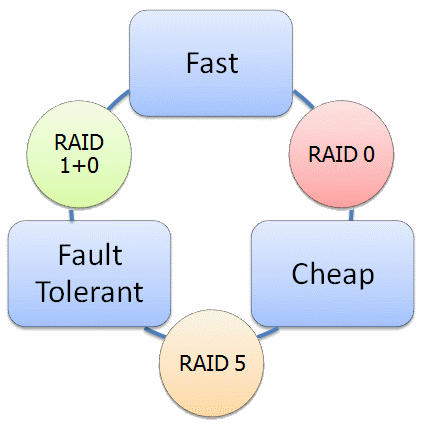
- Fast and Fault Tolerant - RAID 1+0;
- Fast and Cheap, no Fault Tolerance - RAID 0;
- Cheap and Fault Tolerant - RAID 5 or RAID 6.
It may seem that RAID 5 and RAID 6 are expensive, but as the capacity of the array and the number of disks increase, the overhead of the RAID 1+0, both in disks and in controller ports, becomes significant.
Do you really need RAID 0?
If you are planning to build a RAID 0, consider using an SSD instead. Depending on what your requirements are, you may find a better bang for your buck with just one SSD. Also, higher RPM rotational drives (e.g. WD VelociRaptor series) or hybrid drives (like Seagate Momentus XT) may be interesting, depending on your particular usage patterns.
As the capacity requirements increase, two things happen:
- The price difference between an SSD and an array of rotational drives increases.
- The performance of an array of rotational drives increases, because more spindles mean more parallelism. This does not really apply to SSDs because just two or three SSDs would saturate their controller.
So for a large capacity storage a RAID 0 or even RAID 10 array would be cheaper and can still meet the performance requirements for most any practical application. If you do not need large capacity, consider a single SSD instead of a RAID 0 or two SSDs in RAID 1 instead of RAID 10. Also, because RAID does not improve minimum access time, an SSD is by far the best choice for heavy random access.
RAID 5 vs. RAID 6
If you plan on building RAID 5 with a total capacity of more than 10 TB, consider RAID 6 instead.
The problem with RAID 5 is that once a member disk has failed, one more failure would be irrecoverable. To reduce the probability of double failure you need to monitor the array and/or use hot spares. However, even if the RAID rebuild is commenced immediately once the drive fails, it is required to read the entire array in order to complete the rebuild. Although the probability of encountering a read error in any particular read operation is very low, the chance of a read error occurring increases with the array size. It has been widely speculated that the probability of encountering a read error during the rebuild becomes practically significant as the array size approaches 10TB. Although the speculation relies on certain assumptions which are not likely true (refer to the bonus section for details), having to restore from the backup is not pleasant. By the way you do have backups, do you?
RAID 6, being capable of correcting two simultaneous read errors, does not have this problem.
Hot spares
Hot spares are a good addition to a fault-tolerant array. They greatly reduce the impact of monitoring on the array reliability.
If a drive has failed in a fault-tolerant (RAID 1, RAID 10, RAID 5, or RAID 6) array, a vulnerability window opens. If another drive fails during this vulnerability window, the data is lost. Without the hot spare, the rebuild does not commence until someone walks in and physically replaces the failed drive. Hot spare drives allow the controller to commence the rebuild immediately, without having to wait for administrator intervention, thereby reducing the vulnerability window.
The need for a hot spare increases as the number of disks in array increases.
Hot spares are most effective when a single hot spare drive is shared between several arrays. Consider for example an 8-bay NAS. If there is only one RAID 5 array in the NAS, then RAID 6 may be a better option than a hot spare. The hot spare drive just sits there idly; in a RAID 6 array, the same drive would be utilized to improve a read speed. However if you need two RAID 5 arrays, the hot spare drive is shared between these two arrays, reducing the total disk space overhead.
Software RAID is not dead
Do not underestimate a software RAID.
- Software RAID would typically provide the same, if not better reliability than an entry-level server hardware RAID controller. Certainly, a software RAID implemented over motherboard's ATA ports would be noticeably more reliable than a setup involving a $20 FakeRAID card from a corner store.
- Software RAID is easier to move around from server to server. It does not require an identical replacement controller in case of a controller failure, which is sometimes a hindrance with server hardware. Just remember to always move the disks together.
- In RAID 0, RAID 1, and RAID 10, the hardware RAID controller does not provide any computational power benefit because there is nothing to offload.
- Most modern SOHO and small business NAS devices, like Synology, QNAP, or NetGear, use a software RAID (Linux/mdadm).
The significant side effect is that you cannot reliably boot from a software RAID.
Test your RAID
The fault tolerance needs to be tested so that you:
- know exactly how the RAID behaves when a hard drive fails;
- ensure that the RAID is actually capable of surviving a disk failure.
When deploying a fault-tolerant array (RAID 1, RAID 10, RAID 5, or RAID 6), test the system with a simulated disk failure.
- If you have got hot swappable drive bays, just pick a random one and pull the hard drive on a live system.
- If there is no hot swap available, then disconnect one of the disks with the system powered off, then start it.
You need to verify that the system behaves precisely as expected in all aspects. This obviously includes that the array is still accessible. Less obvious, but nonetheless required is to verify that all the notifications were sent and received properly: emails, SMS, and possibly pre-recorded phone calls. Also, check your ability to identify the failed drive easily. Either the appropriate drive bay light should turn red, or the array diagnostic software should give you a clear number of a failed drive bay.
While you are at it, do a simulated power failure by pulling the UPS plug out of its socket. The system should remain online for some predefined period and then gracefully shut down. Ensure that the UPS battery is not fully depleted by the time the shutdown completes.
Obviously, you better do the testing before the array is loaded with the production data, or might have an unplanned RAID recovery incident.
Prevention I - Backup often
Even if your RAID is supposed to be fault tolerant, backup often. Neglecting the backup is by far the worst and the most common mistake people make. They think like "Hey, we got RAID, it is fault-tolerant, made by the best vendor out there, cost us like a small car, so it must be reliable. We do not need backup anymore".

Although the RAID is redundant with respect to hard drive failures, there are still issues that may bring down the entire array, requiring either a restore from a backup or a RAID recovery.
- The RAID controller itself is a single point of failure. The most simple way to get around this is to get rid of the RAID controller by implementing software RAID, but then the software and drivers become the single point of failure.
- The failures of the hard drives may be correlated if they have a single root cause (like a power supply failure involving overvoltage). This is called common mode failure.
- Natural disasters, like floods and hurricanes, are known to take down entire facilities, no matter how redundant a particular system might be. This is why offsite backups are used.
- Last not least, RAID does not protect you against a human error.
Prevention II - Monitor RAID performance
The ability of the RAID to handle failures of its hard drives relies on two things:
- Built-in redundancy of the storage. The RAID has some extra space in it, and the end-user capacity of a fault-tolerant array is always less than the combined capacity of its member disks.
- Diligence of people to provide additional redundant storage should the built-in reserve fail.
Once redundancy is lost because of the first drive failure, the human intervention is needed to correct the problem and restore the required level of redundancy. Redundancy is to be restored quickly, or otherwise there is no point in having the RAID at all.
However, you do not know when to act if you do not monitor the array and the disks often enough.
- Regularly check the SMART status on the drives using appropriate software. With a software RAID, use SpeedFan or HDDLife. With a hardware RAID, use the vendor-supplied monitoring software.
- The so-called "scrubbing" should be used whenever possible. The scrubbing process reads all the data on the array during idle periods or per the predefined schedule. This allows to discover the newly developed bad sectors on the drives before encountering them in actual use. The data can then be relocated away from the unreliable spots or the disk can be replaced.
- Any unexplained drop in the throughput may indicate a problem with one of the hard drives. With certain systems (like a QNAP NAS based on Linux MD RAID) the imminent disk failure may manifest itself as the unit "stalling" long before the drive is declared dead (see QNAP story).
Recover RAID
If a disk fails in a fault-tolerant array such as RAID 5, you just replace the disk and carry on. A fault-tolerant array is just that - designed to provide fault tolerance. However, if there is a controller failure or an operator error, you might end up with a set of disks lacking the array configuration. The set of disks may be either complete (including all the member disks) or incomplete (missing a disk or several disks). While not having a complete disk set slows down the possible recovery, losing one disk is not necessarily irreversible.
You can then send the disk set to the data recovery lab, or try to get the data off yourself using ReclaiMe Free RAID Recovery. Whatever you do, if at all practical you should make disk image files (sector-by-sector copies) of the array member disks. These image files act as an additional safety layer if one more member disk dies while you're busy recovering. Remember to make images of separate member disks, not the entire array.
The most difficult part of RAID recovery is the destriping, the process of converting the striped array to the contiguous set of sectors as it is on a regular hard drive. ReclaiMe Free RAID Recovery does exactly that, giving you a choice of several output options, and at no cost. You can even make it interact with certain third-party data recovery tools, providing necessary preprocessing to make them capable of handling the RAID.
Bonus Fear, Uncertainity, and Doubt - Unrecoverable errors in RAID 5 revisited
There is a known and widely discussed issue with RAID 5. If one drive in the array fails completely, then during the rebuild there may be a data loss if one of the remaining drives encounters an unrecoverable read error (URE). These errors are relatively rare, but sheer size of modern arrays leads to speculation that one cannot even read the entire array reliably (without encountering a read error).
There are some pretty scary calculations available on the Internet. Some are concluding that there is as much as 50% probability of failing the rebuild on the 12TB (6x2TB) RAID 5.
The calculation goes like this: let's say we have a probability p of not being able to read the bit off the drive. Then, q = 1 - p is the probability of the successful read, per bit. To be able to rebuild the RAID 5 array of N disks C terabytes each, one needs to read C*(N-1) terabytes of data. Let's denote the number of bits to read as b = C * (N-1) * 8 * 1012 and we arrive at the probability of successfully completing the rebuild P = qb.
The value of p is provided in the hard drive specification sheet, typically around 1015 errors per bit read.
Specified URE
1014
1015
1016
Probability of rebuild failure for 6x 2TB drives
~55%
~10%
~0%
These calculations are based on somewhat naive assumptions, making the problem look worse than it actually is. The silent assumptions behind these calculations are that:
- read errors are distributed uniformly over hard drives and over time,
- the single read error during the rebuild kills the entire array.
Both of these are not true, making the result useless. Moreover, the whole concept of specifying a bit-level stream-based error rate for a block-based device which cannot read less than 512 bytes of data per transaction seems doubtful.
The original statement can be transformed into something more practical:
The statement "There is a 50% probability of being not able to rebuild a 12TB RAID 5" is the same as "If you have a 10TB RAID 0 array, there is a 50% probability of not getting back what you write to it, even if you write the data and then read it back immediately." That's assuming the same amount of user data on both arrays and 2TB hard drives. Still, nobody declares RAID 0 dead.
This can be reformulated even further: assuming 100MB/sec sustained read speed, we can say "There is a 50% chance that a hard drive cannot sustain a continuous sequential read operation for 30 hours non-stop", which just does not look right. 30 hours is the approximate time to read 10TB of data at 100MB/sec.
Bonus Modern Marvels – BTRFS, ZFS, Microsoft Storage Spaces
As of late, there is some drift to create hybrid solutions combining filesystem and RAID into a single module, or a single storage layer, whichever way you call it. If you have a choice between one of this hybrid filesystems and a traditional RAID controller, go with the traditional RAID whenever possible.
This includes (but is obviously not limited to)
- Microsoft Storage Spaces, which break horrifically. Supposedly designed to work on lower-end, corner-store-grade hardware, Storage Spaces do not scale that well on the low-end hardware. Any large (as in more than two drives) setup with Storage Spaces will land you in hot water sooner or later.
- BTRFS, which is just plain not ready for production in its RAID part as of this writing (early 2016). Illustrations are available en masse in the BTRFS mailing list.
- ZFS, which looks most solid of them all, but still not stable enough on a large pile of low-end hardware.
Заключение
От себя добавлю следующее
- mdadm наше всё
- raid 5 - плохо, raid 6 - хорошо
- fake raid использовать нельзя
- software raid в windows 7 и 10 - плохо
- microsoft storage spaces в windows 10 - плохо, вероятно в windows server это работает, как надо
- аппаратные raid-контроллер без bbu (battery backup unit) плохое решение
- xfs отлично переживает внезапные отключения, но лучше использовать ups
- btrfs игрушка
- zfs и raidz супер, но на bsd
- raid10 на ssd от samsung успешно работают 5+ лет на высокой нагрузке


Discussion